
Subset Construction – Theory
This guide follows a guide for NFA Construction. If this is your first article here it might help to start at the Compiler Construction Guide.
Subset construction is a tool, in computational theory, to convert a Nondeterministic Finite Automaton into a Deterministic Finite Automaton. For something such as NFA construction it may seem counterintuitive since you are constructing an NFA rather than a DFA. But if you remember back to the theory of computation, every DFA is also an NFA, we are not breaking any rules transitioning from a DFA to an NFA.
The question you may have is why bother? If you think back to the end of the implementation section you had figure 7, repeated here again as figure 1. We assumed that every transition without a symbol was an epsilon transition. This being the case, the NFA is much larger than we would like it to be. There are many epsilon transitions that are completely unnecessary.

To handle this we use what is called subset construction. With subset construction, we can combine states into sets of states and follow along the path of the original NFA. This goes hand in hand with the epsilon-closure function. The epsilon-closure function takes a state and returns a set of all states reachable with epsilon transitions. For example with the NFA above, if we called the epsilon closure of state 12, we would receive the set {12, 4, 2, 0, 10, 6, 8}. We include 12 in our result because if we left it out we could be losing a transition, technically we can transition from 12 to 12 with an epsilon transition. This function will help us break down the NFA into a handful of states.
Step 1: Use using epsilon closure and transition
To begin we take the epsilon closure of the first state 12, which we did above. Now our new first state is the set of states {4, 2, 0, 10, 6, 8}. From there we use our alphabet to construct the transitions to new states. So we first transition on the symbol a, which results in {3} and then we take the epsilon closure of that which gives us {3, 5}. Next we do that with b, 1, and 2 which result in {1, 5}, {7, 11}, and {9, 11} respectively.
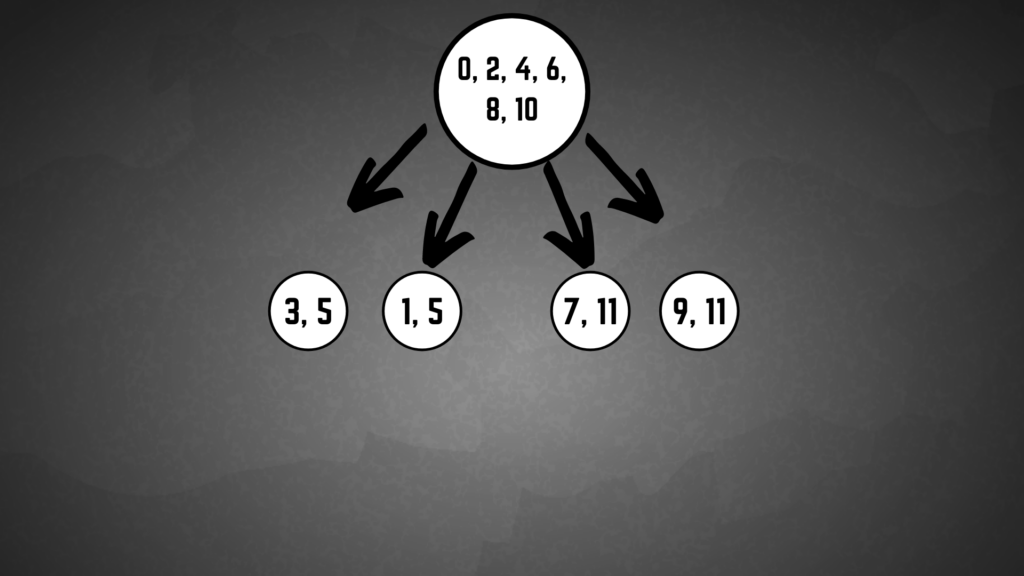
Step 2: Transition to failing states
Next, we need to transition from each of these states to the next ones. For this example we can see pretty easily, especially knowing that the regular expression is simply a|b|1|2, anything that is given to the NFA will result in a failing state. This is represented with an empty set.

Step 3: Label final states
Finally, we have to add the accepting states. For this, we recognize that any set with a previously accepted state must also be an accepted state since it was reachable via an epsilon transition. That means with this new NFA we have 4 accepting states.

We originally had 12 states, now after subset creation, we only have 6. We have increased the efficiency of this NFA quite a bit, but that doesn’t mean that the subset construction method does not have flaws. Notice that with every state we can be any number of states. That means in theory we can have 2|S| states where S is the set of states in the original NFA. This is the worst-case scenario, however, and due to the manner of constructing the NFAs that we are taking, we will always be given an equal or better NFA.
Books
Listed below are a few of my favorite books that taught me a fair amount of compiler construction. If you have books that benefited you on this topic, please share them in the comments below and expand this list!
- Introduction to Languages and the Theory of Computation, By John Martin
- Compilers: Principles, Techniques, and Tools, By Alfred Aho, Monica Lam, Ravi Sethi, and Jeffrey Ullman
