
Enhancements
This guide follows a guide for NFA Construction. If this is your first article here, it might help to start at the NFA Construction Guide.
In the list of possible enhancements about improving the concatenation regular expression to NFA. In this article, we will go in-depth with time complexities and space complexities and argue whether or not this is a good enhancement for your lexer.
To begin, let’s establish a baseline. We will use our first implementation to build a baseline of going from regular expression to epsilon closure.
Method 1
This implementation aims to create a new initial and new final state for the NFA we are constructing. Then we make epsilon transitions between the new initiative and the first machine’s initial state, then from the first machine’s final state to the initial state of the second, and one last one from the final state to the second machine to the new final state.
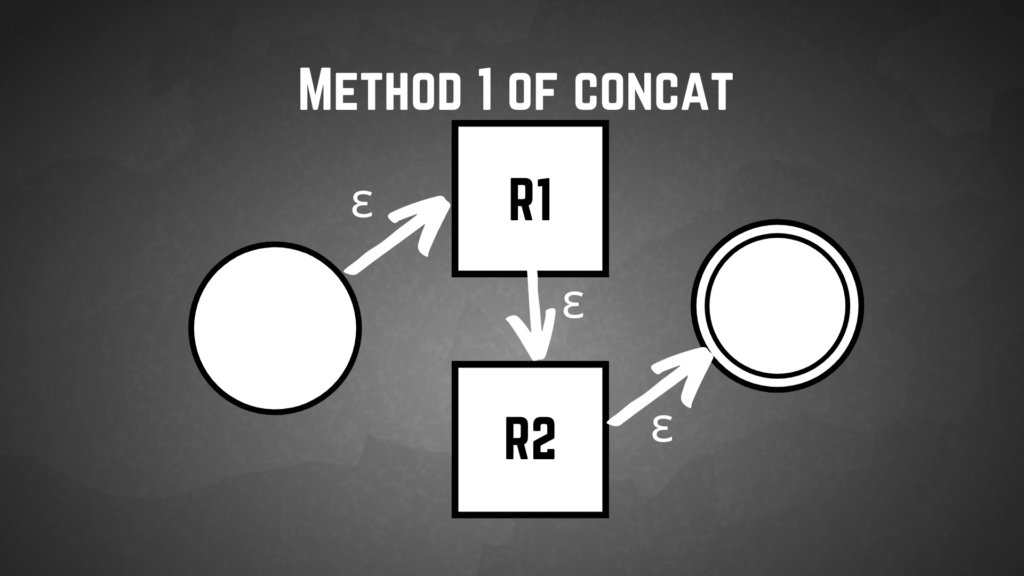
We will use this pseudocode as our example of constructing the NFA.
function construct-concat-NFA(machine-1, machine-2):
initial-state = new InitialState()
final-state = new FinalState()
states = initial-state, final-state, machine-1.states, machine-2.states
transition2 = [
new E-Transition(initial-state, machine-1.init),
new E-Transition(machine-1.final, machine-2.init),
new E-Transition(machine-2.final, final-state),
machine-1.transitions,
machine-2.transitions,
]
return new NFA(states, initial-state, {final-state}, transitions)Since constructors are constant time, this whole function is considered to be O(1).
That being said it’s we want a way to determine how many states are created. For this, we will consider strings to be the only thing used by this example. We know that strings have one symbol in each level of the concat tree. This means that we essentially have a list. We say that n is the size of the string, then we will declare a function S, which tells us based on the length how many states we have.
We can build this function in a couple of ways, but it is simple enough to write out a couple of examples and simply see the pattern. A string of length 2 will have 6 states; of 3, we have 10; of 3, we have 14. For each character, we have an increase of 4 starting with 6 states. This means our function is S(n) = 2 + 4(n-1).
The last thing we need to know is the number of transitions in this build. For this, we can see that a string of length 2 has 5 transitions, of length 3 has 9, of length, has 13. This leads us to a function for transitions of T(n) = 1 + 4(n-1).
Method 2
In method 2, we cut out the new initial state and new final state from the last one. This one will clearly help in decreasing the states.
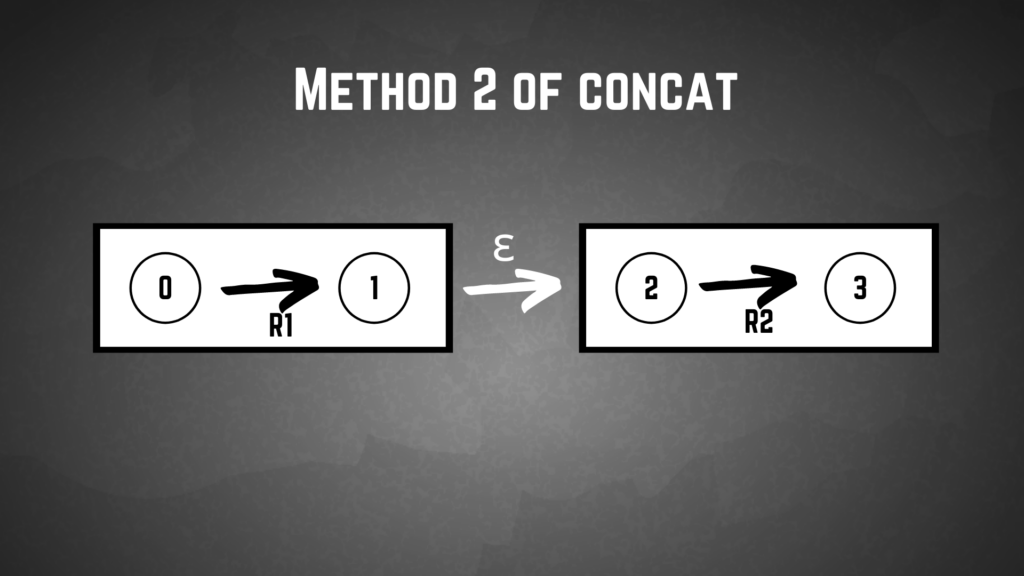
function construct-concat-NFA(machine-1, machine-2):
initial-state = new InitialState()
final-state = new FinalState()
states = machine-1.states, machine-2.states
transition2 = [
new E-Transition(machine-1.final, machine-2.init),
machine-1.transitions,
machine-2.transitions,
]
return new NFA(states, machine-1.init, machine-2.final, transitions)With this, we once again see constant time with the construction, O(1).
The states we see can use the same idea as the last method to create out function S. A string of length 2 has 4 states, of length 3 has 6 states, of length 4 has 6 states. It is clear that every character adds exactly 2 states. So our function is S(n) = 2n.
Next, we need our number of transitions again. We look at string lengths 2, 3, and 4 and find transitions of 3, 5, and 7 respectively. That means T(n) = 1 + 2(n-1).
Method 3
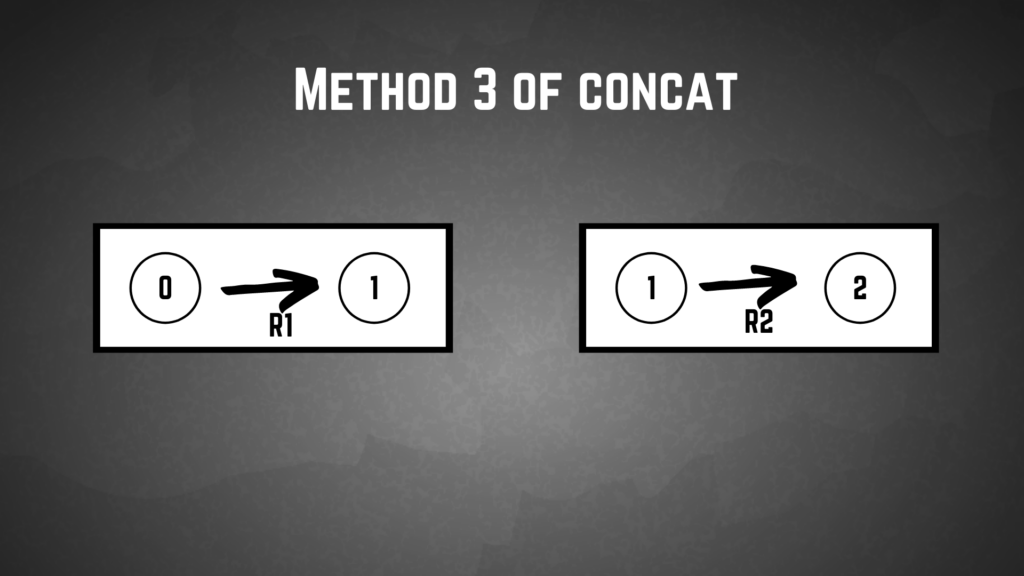
function construct-concat-NFA(machine-1, machine-2):
initial-state = new InitialState()
final-state = new FinalState()
machine-1.final.transitions -> machine-2.init
states = machine-1.states - machine-1.final, machine-2.states
transitions = machine-1.transitions, machine-2.transitions
return new NFA(states, machine-1.init, machine-2.final, transitions)Once again, the construction here is done in constant time, O(1). However, it is important to point out that this can go exponential or linear very easily, depending on your implementation. If you have a function that replaces the state by following or recreating the path, this is easy to get caught in. That being said, it is possible to do this in constant time for some implementations.
Moving on to the states, we notice there is one less state in this build than the last. But we will still find the pattern just the same manner as before. For a string of length 2, we have 3 states; of length 3, we have 4 states; of length 4, we have 5 states. This means our function is S(n) = n + 1.
Now we just need our number of transition functions again. We see strings of lengths 2, 3, and 4 with transitions of sizes 2, 3, 4. This one is simple as we just have T(n) = n.
Transitioning States
Whatever implementation we choose, we will need to transition from state to state, or in the case of subset-construction, multiple states to multiple states. All we need to know for this function is the time complexity as it holds nothing in memory for longer than its duration. However, we will consider both functions as we will need them both.
def transition(transitions-list, state, symbol):
states = {}
for transition in transitions-list:
if transition.symbol == symbol and transition.state == state:
states.add(transition.final)
return statesThis time complexity might seem odd at first because the initial thinking is O(n) because of the transition list, but it is simply constant time for strings. This is because each state will only have one transition in its transition list. This is string-specific, so that should be kept in mind. But with that being said, we have O(1) for this function.
Next, we have to make one for lists of states.
def transition-states(transitions-list, states, symbol):
final-states = {}
for state in states:
final-states = final-states.union(transition(transition-list, state, symbol)
return final-statesThis we say is O(m), where m is the number of states in the states variable.
Epsilon Closure
Epsilon closure is a big part of this build. But we will assume that we have our epsilon closure function memoized so that we only have to compute it once. This is a good implementation, and it also allows us the ability to see the benefits of our methods above truly.
To begin, we will assume our epsilon closure to follow the pseudo-code below. This function takes the delta function of the NFA and states to transition from.
function epsilon-closure(delta-func, states):
visited = new Set()
stack = states
for state in states:
current-state = stack.pop()
visited.add(current-state)
stack = stack.union(delta-func(state, "EPSILON"))
return visitedThe epsilon-closure function here really only has two cases. The state we are on is one of the epsilon transition states from method 1 or 2, or if it is on a symbol transition state.
In the case when we are on an epsilon transition state, we have 1 loop to make. We will call this constant time, but rather than blanket O(1), we will say O(2) as it has to check 2 states.
In the case we are on a symbol transition state, we never loop. This is a constant time of O(1).
Results
Methods 1 and 2 are not the optimal solutions to this problem, although they work, and the epsilon transition function’s implementation truly saves them. However, they both lack in the space category. Both of these have a lot more states and a lot more transitions compared to method 3.
In the end method, 3 is faster on average and saves a massive amount of space while storing the NFA. This solution should be implemented rather than the other two methods.
Books
Listed below are a few of my favorite books that taught me a fair amount of compiler construction. If you have books that benefited you on this topic, please share them in the comments below and expand this list!
- Introduction to Languages and the Theory of Computation, By John Martin
- Compilers: Principles, Techniques, and Tools, By Alfred Aho, Monica Lam, Ravi Sethi, and Jeffrey Ullman
