
Subset Construction – Implementation
This guide follows a guide for NFA Construction. If this is your first article here it might help to start at the Compiler Construction Guide.
To begin implementing subset construction, we need to make a minor change to our transition function. Before, we only passed a single state into our transition function. In subset construction, we saw that we often work in multiple states; we will want our transition function to take multiple states. This is simple to implement because we can check if the state variable is a set of states or a single state.
def transition(NFA, state, symbol):
states = set()
if type(state) == set:
for s in state:
states = states ∪ {transition(s)}
else:
for NFA-transition in NFA[4]:
if NFA-transition[1] == state and NFA-transition[2] == symbol:
states = states ∪ {NFA-transition[3]}
return states
def compile-NFA(NFA):
return ["COMPILED-NFA", NFA, (state, symbol) => transition(NFA, state, symbol)]Now we can implement an epsilon closure function for our lexer. Remember that epsilon closure takes an NFA and either a state or a set of states and returns a set of states that are reachable from the given state or states purely on epsilon transitions. This shouldn’t be too complex of a function.
We will use a stack to keep track of the states we are visiting and a set of reachable states. We will use our set to avoid looping by removing the overlapping states between the set and the stack. Then we will continually call the transition function until no more transitions can be made.
def epsilon-closer(compiled-NFA, states):
reachable-states = set()
stack = new-stack(states)
while stack is not empty:
current-state = {stack.pop()}
reachable-states = reachable-states ∪ current-state
new-states = compiled-NFA[2](current-state, "EPSILON")) - reachable-states
stack = stack ∪ new-states
return reachable-statesNow that we have our epsilon transition, we can begin subset construction. For this, we will create a 2-dimensional array rather than a new NFA. This will be to increase the efficiency of parsing. The idea is that the 2-dimensional array will act as the transition function, and that is all we need to tokenize our source code.
To do this, we need some helper functions. The first helper function we will create is a function to get all of the possible subset states. This function will need a compiled NFA, a state, an alphabet, and a set of states. The compiled NFA will provide us with a transition function and allow us to use our epsilon-closure function. The state is a set of states, and this set of states represents one of our new subset constructed states. Initially, this is the epsilon-closure of our initial state. The alphabet is needed so that we can build the 2-dimensional array. And lastly, we have a set of states; this allows us to keep track of the states we visit.
def get-subset-states(compiled-NFA, state, alphabet, states={}):
if state in states:
return states
states = states ∪ {state}
if state is an empty set:
return states
for symbol in alphabet:
state_ = compiled-NFA[2](state, symbol)
state_ = epsilon-closer(compiled-NFA, state_)
if state_ not in states:
states = states ∪ get-subset-states(compiled-NFA, state_, alphabet, states)
return statesWith this helper function, we can now build our 2-dimensional array with ease. This may have a potentially easier solution that combines the two, but since we will need the list of states later, it doesn’t seem to hurt to take the extra time.
We create our next helper function, which will transition from state to state in our new subset construction. This function is relatively simple but very powerful. This function will take a state and symbol to transition from just as before and take the 2-dimensional array that we are making, a list of the states we produced with our get-subset-states function, and the alphabet. Then is looks inside the 2-dimensional array at its corresponding indexes.
def subset-transition(state, symbol, delta, states, alphabet):
i = states.index-of(tuple(state))
j = alphabet.index-of(symbol)
return delta[i][j]Next, we want the final helper function, check-successful-state. This function will check if a state is a successful state or not. It will look through all of the equivalent states from the NFA and check if it contains a successful one, and if it does, it will return that said state. If the state is not successful, it will return false.
def successful-state(successful-states, state):
for success-state in successful-states:
if success-state in state:
return success-state
return FalseNow that we have all of the helper functions, we can create another object. This one will be a subset construction. We will represent it again with an array but this time consisting of an initial state, transition function, and a successful state checker.
To build this subset construction, we need to take the epsilon closure of the initial state in the NFA. Then we need to get a list of the possible subset states using the helper function we made before. Once we have those, we can begin looping through the subset states to build a 2-dimensional array. From there, we will build some lambda functions with the other helper functions and return the array.
def build-subset-construction(compiled-NFA, alphabet):
initial-state = epsilon-closer(compiled-NFA, {compiled-NFA[1][2]})
subset-states = list(get-subset-states(compiled-NFA, initial-state, alphabet))
delta = []
for state in subset-states:
state_ = set(state)
sub-delta = []
for symbol in alphabet:
sub-delta += [epsilon-closer(compiled-NFA, compiled-NFA[2](state_, symbol))]
delta += [sub-delta]
transition = lambda state, symbol: subset-transition(state, symbol, delta, subset-states, alphabet)
successful-state_ = lambda state: successful-state(compiled-NFA[1][3], state)
return ["SUBSET_CONSTRUCTION", initial-state, transition , successful-state_]Now, if we look back to our previous example, we have taken the following NFA.

Created the idea of it being represented as the following.

And now, pragmatically, we have.
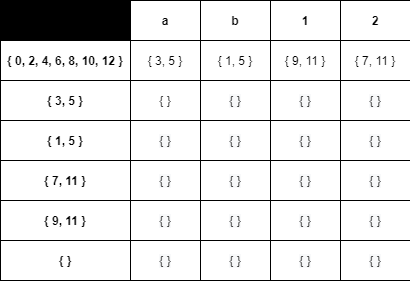
In the next section, we will begin to apply this table and start tokenizing our source program.
Books
Listed below are a few of my favorite books that taught me a fair amount of compiler construction. If you have books that benefited you on this topic, please share them in the comments below and expand this list!
- Introduction to Languages and the Theory of Computation, By John Martin
- Compilers: Principles, Techniques, and Tools, By Alfred Aho, Monica Lam, Ravi Sethi, and Jeffrey Ullman
